
시작하며: 도메인 주도 설계란?
도메인 주도 설계(DDD)는 비즈니스의 인사이트를 소프트웨어 개발에 녹여내는 방법론입니다. 유비쿼터스 언어(Ubiquitous Language), 바운디드 컨텍스트(Bounded Context) 등의 개념을 핵심으로 하며, 크게 전략적 설계와 전술적 설계로 나뉩니다.
이번 포스트에서는 NestJS 프레임워크로 전술적 설계를 어떻게 적용할 수 있는지에 초점을 맞추고자 합니다. 만약 DDD 자체가 생소하다면, 본 포스트에 앞서 DDD 개념을 한 번 더 공부해보시는 것을 권장합니다. 추후 DDD 전반에 걸친 시리즈 글로 개념을 더 자세히 다룰 예정이니 많은 기대 부탁드립니다.
전술적 설계에서 활용할 개념
1. 바운디드 컨텍스트(Bounded Context)
바운디드 컨텍스트는 DDD의 전략적 설계에서 가장 핵심적인 요소 중 하나입니다.
- 의미 : 말 그대로 “경계가 정해진 컨텍스트”를 의미합니다. 여기서 ‘경계’(Boundary)는 하나의 도메인을 다른 도메인과 분리해주는 역할을 합니다.
- 역할 : 각 컨텍스트 내부에서만 유효한 유비쿼터스 언어(Ubiquitous Language) 를 정립하고, 이를 기반으로 도메인 모델을 정의하여 혼란을 최소화합니다.
- 중요성 : 여러 팀 혹은 여러 기능이 뒤섞이는 대규모 프로젝트에서는, 각 팀이 맡은 컨텍스트(도메인)를 명확히 구분해야 의사소통이 쉬워지고, 모델 충돌을 방지할 수 있습니다.
예를 들어, “예약 시스템”을 구축한다고 가정해 봅시다.
- 예약(Reservation) 컨텍스트와 결제(Payment) 컨텍스트가 각각 존재할 수 있습니다.
- 결제 컨텍스트가 예약 컨텍스트의 도메인 객체를 직접 참조하기보다는, API 나 이벤트 를 통해 느슨하게 필요한 정보만 주고받도록 설계하는 것이 바운디드 컨텍스트의 핵심입니다.
이렇게 바운디드 컨텍스트를 먼저 나눈 뒤, 내부에 어떤 엔티티, 어떤 값 객체, 어떤 서비스가 필요한지 정의해 나가는 것이 전술적 설계의 출발점이 됩니다.
2. 엔티티와 값 객체
- 엔티티(Entity)
: 고유한 식별자
(ID)
를 가진 객체로, 시간이 지나도 동일성을 유지합니다.
예약그 자체가 엔티티가 될 수 있겠네요. - 값 객체(Value Object)
: 불변의 특성을 가지며, 단순히 값 자체로서 의미를 갖는 객체입니다.
예약에서 price에 대한 정보들을reservationPrice라는 값 객체로 따로 정의할 수 있습니다.
3. 애그리거트
- 애그리거트(Aggregate)
: 관련 있는 엔티티와 값 객체를 하나의 단위로 묶어, 외부와의 경계를 명확히 하는 역할을 합니다. 이를 통해 데이터의 일관성을 유지할 수 있습니다. 가령
User애그리거트에서는UserProfile,UserProgress등의 엔티티가 존재할 수 있습니다. - 애그리거트 루트(AggregateRoot)
: aggregate의 중심이 되는 하나의 객체를 뜻합니다. 보통 AggregateRoot가 같은 Aggregate 내부 여러 엔티티들을 향한
단일 진입점
역할을 합니다.
User클래스가User애그리거트의 여러 엔티티를 아우르는 Root가 될 수 있죠. - 도메인 이벤트(Domain Event)
: 도메인에서 특정 (도메인) 로직을 수행하면서 발생하는 중요한 사건을 표현합니다. 가령 유저가 생성 되었을 때,
유저 생성됨이벤트가 발행될 수 있습니다. 유저 생성이라는 로직과 연관되어 움직여야할 외부 도메인에선, 해당 이벤트를 구독함으로 느슨한 결합을 유지하며 외부 도메인과 연관된 로직을 유지할 수 있죠.
NestJS-프로젝트 셋업하기
디렉토리 설정
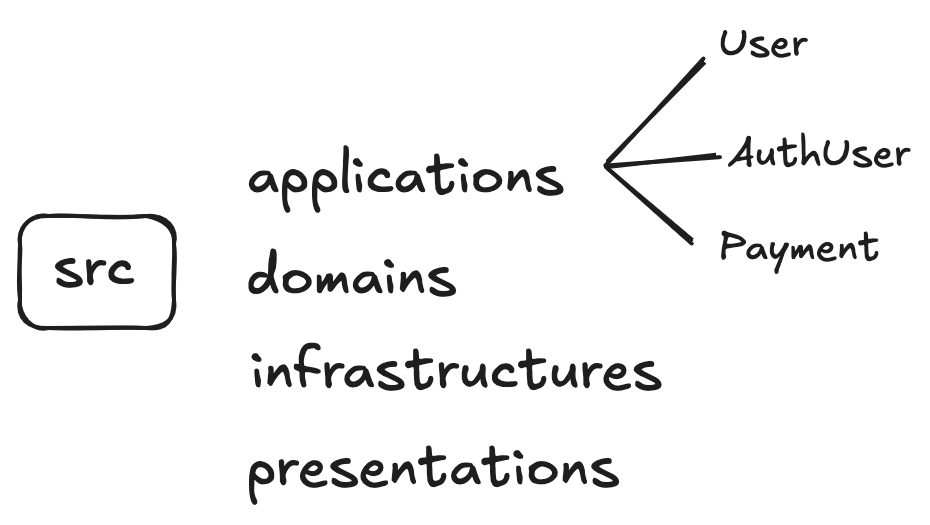
아래와 같이 DDD 기반으로 NestJS 프로젝트의 디렉토리 구조를 설계할 수 있습니다. service 디렉토리는 Bounded Context별로 나누고, 추후 개별 마이크로 서비스로의 전환을 도모합니다. shared 디렉토리는 공통 모듈을 포함하는 구조로 설계합니다.

service외의 디렉토리는 각자 취향에 맞게 설계하시면 됩니다. 우선 하나하나 설명을 하기 앞서 Command와 Query를 나눈 이유는 읽기와 쓰기 책임을 나눈다는 CQRS 패턴을 적용한 것인데, 이에 대해는 여기서 다루기 방대해 아티클을 따로 쓰도록 하겠습니다.
왜 읽기와 쓰기를 나누는가?
Command 작업고 Query 작업을 나누게 된 이유를 간략하게 설명하면, 도메인 주도 설계의 가장 큰 효용은 쓰기 작업 등을 수행할 때 도메인 모델을 기점으로 각각 데이터를 안정적인 생명주기로 다룰 수 있다는 건데, 읽기 작업에선 Domain 계층을 활용하는 것이 쓸모가 정말 없습니다. 오히려 뷰를 그리기 위해 여러 바운디드 컨텍스트가 걸친 데이터를 읽어야 할 때, Aggregate간의 엄밀한 독립성을 보장한 DDD 안에서 하려고 하면 각각 도메인들을 조인을 못하고 따로따로 불러와야되어 많은 오버헤드가 발생합니다
DDD는 백엔드 아키텍처가 아니라, 기획부터 개발까지 이어지는 설계 전략인지라, query에서 DDD를 하지 않는다는 것은 아닙니다만, 조회 로직의 특성상 쓰기 작업과는 좀 다른 형태로 전술적 설계가 되어야 합니다.
사실상 저희가 지금 이 포스트에서 다루려는건, 쓰기 작업에서의 DDD 구현이라는 것을 인지해주시기 바랍니다.
Layered Architecture
기본적으로 여느 백엔드가 그러하듯 layered Architecture를 채택합니다. 계층은 아래와 같이 나눕니다.
- applications : 응용 서비스 계층
- infrastructures : 외부 인프라(db, queue 등)와 맞닿는 계층
- presentations : 서버가 외부에 표현되는 계층 (rest controller, rpc controller 등)
- domain : AggregateRoot, Domain Entity, VO 등 도메인과 관련된 계층
보통의 레이어드 아키텍처에서 주로 볼 수 있는 계층들로 나누었구요! infrastructure 계층 대신 persistence 계층으로 정의할 지는 취향 및 프로젝트 성질에 따라 취향 껏 쓰시면 되겠습니다.
구현 예시로 user-management Bounded-Context 내부 구조를 보여드리겠습니다.

위의 예시에서 눈에 띄게 확인할 수 있는 포인트는
- 계층보다 도메인이 상위에 위치한다.
- 계층은 모듈 단위로 반복된다.
- 모듈간의 위계가 존재한다.
정도입니다. 먼저 1. 계층보다 도메인이 상위에 위치한다.에 대해 자세히 살펴보죠
도메인 vs 계층
서비스 아키텍처 설계는
계층이 우선 시 되는 경우
도메인이 우선 시 되는 경우
